/*personal notes of renzo diomedi*/
~ 00000101 ~
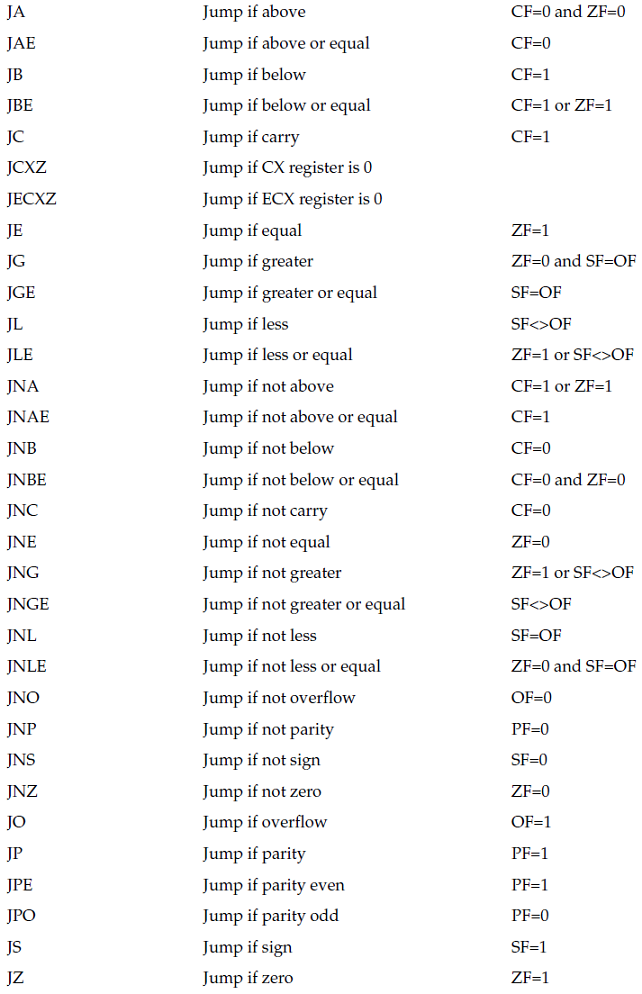

BRANCH PREDICTION
When a branch instruction is encountered, the processor out-of-order engine must determine the next
instruction to be processed. The out-of-order unit utilizes a separate unit called the branch prediction
front end to determine whether or not a branch should be followed. The branch prediction front end
employs different techniques in its attempt to predict branch activity. When creating assembly language
code that includes conditional branches, you should be aware of this processor feature.
.... Unconditional branches
With unconditional branches, the next instruction is not difficult to determine, but depending on how
long of a jump there was, the next instruction may not be available in the instruction prefetch cache.
When the new instruction location is determined in memory, the out-of-order engine must first determine
if the instruction is available in the prefetch cache. If not, the entire prefetch cache must be cleared,
and reloaded with instructions from the new location. This can be costly to the performance of the
application.
.... Conditional branches
Conditional branches present an even greater challenge to the processor. For each unconditional branch,
the branch prediction unit must determine if the branch should be taken or not. Usually, when the outof-
order engine is ready to execute the conditional branch, not enough information is available to know
for certain which direction the branch will take.
Instead, the branch prediction algorithms attempt to guess which path a particular conditional branch
will take. This is done using rules and learned history. Three main rules are implemented by the branch
prediction algorithms:
❑ Backward branches are assumed to be taken.
❑ Forward branches are assumed to be not taken
❑ Branches that have been previously taken are taken again.
Using normal programming logic, the most often seen use of backward branches (branches that jump to
previous instruction codes) is in loops. For example, the code snippet
movl $100, $ecx
loop1:
addl %cx, %eax
decl %ecx
jns loop1
will jump 100 times back to the loop1 label, but fall through to the next instruction only once. The first
branching rule will always assume that the backwards branch will be taken. Out of the 101 times the
branch is executed, it will only be wrong once.
Forward branches are a little trickier. The branch prediction algorithm assumes that most of the time
conditional branches that go forward are not taken. In programming logic, this assumes that the code
immediately following the jump instruction is most likely to be taken, rather than the jump that moves
over the code. This situation is seen in the following code snippet:
movl -4(%ebp), %eax
cmpl -8(%ebp), %eax
jle .L2
movl -4(%ebp), %eax
movl %eax, 4(%esp)
movl $.LC0, (%esp)
call printf
jmp .L3
.L2:
movl -8(%ebp), %eax
movl %eax, 4(%esp)
movl $.LC0, (%esp)
call printf
.L3:
It is the code snippet from the analysis of the C program ifthen. The code
following the JLE instruction handles the “then” part of the If statement. From a branch prediction point
of view, we can now see the reason why the JLE instruction was used instead of a JG instruction. When
the compiler created the assembly language code, it attempted to maximize the code’s performance by
guessing that the “then” part of the If statement would be more likely to be taken than the “else” part.
Because the processor branch prediction unit assumes forward jumps to not be taken, the “then” code
would already be in the instruction prefetch cache, ready to be executed.
The final rule implies that branches that are performed multiple times are likely to follow the same path
the majority of the time.
The Branch Target Buffer (BTB) keeps track of each branch instruction performed
by the processor, and the outcome of the branch is stored in the buffer area.
The BTB information overrides either of the two previous rules for branches.
For example, if a backward
branch is not taken the first time it is encountered, the branch prediction unit will assume it will not be
taken any subsequent times, rather than assume that the backwards branch rule would apply.
The problem with the BTB is that it can become full. As the BTB becomes full, looking up branch results
takes longer, and performance for executing the branch decreases.
/* for.c */
#include
int main()
{
int i = 0;
int j;
for (i = 0; i < 1000; i++)
{
j = i * 5;
printf(“The answer is %d\n”, j);
}
return 0;
}
$ gcc -S for.c
$ cat for.s
.file “for.c”
.section .rodata
.LC0:
.string “The answer is %d\n”
.text
.globl main
.type main, @function
main:
pushl %ebp
movl %esp, %ebp
subl $24, %esp
andl $-16, %esp
movl $0, %eax
subl %eax, %esp
movl $0, -4(%ebp)
movl $0, -4(%ebp)
.L2:
cmpl $999, -4(%ebp)
jle .L5
jmp .L3
.L5:
movl -4(%ebp), %edx
movl %edx, %eax
sall $2, %eax
addl %edx, %eax
movl %eax, -8(%ebp)
movl -8(%ebp), %eax
movl %eax, 4
movl $.LC0, (%esp)
call printf
leal -4(%ebp), %eax
incl
jmp .L2
.L3:
movl $0, (%esp)
call exit
.size main, .-main
.section .note.GNU-stack,””,@progbits
.ident “GCC: (GNU) linux distro”
Similar to the if statement code, the for statement code first does some housekeeping with the ESP and
EBP registers, manually setting the EBP register to the start of the stack, and making room for the variables
used in the function. The for statement starts with the .L2 label:
.L2:
cmpl $999, -4(%ebp)
jle .L5
jmp .L3
The condition set in the for statement is set at the beginning of the loop. In this case, the condition is to
determine whether the variable is less than 1,000. If the condition is true, execution jumps to the .L5
label, where the for loop code is. When the condition is false, execution jumps to the .L3 label, which is
the ending code.
The For loop code is as follows:
.L5:
movl -4(%ebp), %edx
movl %edx, %eax
sall $2, %eax
addl %edx, %eax
movl %eax, -8(%ebp)
movl -8(%ebp), %eax
movl %eax, 4(%esp)
movl $.LC0, (%esp)
call printf
The first variable location (the i variable in the C code) is moved to the EDX register, and then moved to
the EAX register. The next two instructions are mathematical operations. The CALL instruction performs a left
shift of the EAX register two times. This is equivalent to
multiplying the number in the EAX register by 4. The next instruction adds the EDX register value to the
EAX register value. Now the EAX register contains the original value multiplied by 5 (tricky).
After the value has been multiplied by 5, it is stored in the location reserved for the second variable (the
j variable in the C code). Finally, the value is placed on the stack, along with the location of the output
text, and the printf C function is called.
The next part of the code gets back to the for statement function:
leal -4(%ebp), %eax
incl (%eax)
jmp .L2
The LEA instruction loads the effective memory address of the declared
variable into the register specified. Thus, the memory location of the first variable (i) is loaded into the
EAX register. The next instruction uses the indirect addressing mode to increment the value pointed to by
the EAX register by one. This in effect adds one to the i variable. After that, execution jumps back to the
start of the for loop, where the I value will be tested to determine whether it is less than 1,000, and the
whole process is performed again.
From this example you can see the framework for implementing for loops in assembly language. The
pseudocode looks something like this:
for:
jxx forcode ; jump to the code of the condition is true
jmp end ; jump to the end if the condition is false
forcode:
< for loop code to execute>
jmp for ; go back to the start of the For statement
end:
The while loop code uses a format similar to the For loop code.
TO OPTIMIZE
conditional branch instructions
can have a detrimental effect on the prefetch cache. As branches are detected in the cache, the out-of-order
engine attempts to predict what path the branch is most likely to take. If it is wrong, the instruction
prefetch cache is loaded with instructions that are not used, and processor time is wasted. To help solve
this problem, you should be aware of how the processor predicts branches, and attempt to code your
branches in the same manner. Also, eliminating branches whenever possible will greatly speed things
up. Examining loops and converting them into a sequential series of operations enables the processor
to load all of the instructions into the prefetch cache, and not have to worry about branching for
the loop.
The most obvious way to solve branch performance problems is to eliminate the use of branches whenever
possible. Intel has helped in this by providing some specific instructions.
CMOV instructions were specifically
designed to help the assembly language programmer avoid using branches to set data values. An example
of using a CMOV instruction is as follows:
movl value, %ecx
cmpl %ebx, %ecx
cmova %ecx, %ebx
The CMOVA instruction checks the results from the CMP instruction. If the unsigned integer value in the
ECX register is above the unsigned integer value in the EBX register, the value in the ECX register is
placed in the EBX register. This functionality enabled us to create the cmovtest.s program, which determined
the largest number in a series without a bunch of jump instructions.
Sometimes duplicating a few extra instructions can eliminate a jump. This small instruction overhead
will easily fit into the instruction prefetch cache, and make up for the performance hit of the jump itself.
An example:
loop:
cmp data(, %edi, 4), %eax
je part2
call function1
jmp looptest
part2:
call function2
looptest:
inc %edi
cmpl $10, %edi # 10 - edi =
jnz loop
The loop calls one of two functions, depending on the value read from the data array. After the function
is called, a jump is made to the end of the loop to increase the index value of the array and loop back to
the start of the loop. Each time the first function is called, the JMP instruction must be evaluated to jump
forward to the looptest label. Because this is a forward branch, it will not be predicted to be taken, and
a performance penalty will result.
To change this, you can modify the code snippet to look like the following:
loop:
cmp data(, %edi, 4), %eax
je part2
call function1
inc %edi
cmp $10, %edi
jnz loop
jmp end
part2:
call function2
inc %edi
cmp $10, %edi
jnz loop
end:
Instead of using the forward branch within the loop, the looptest code was duplicated within the first
function code section, eliminating one forward jump from the code.
UNROLL LOOPS
movl values, %ebx
movl $1, %edi
loop:
movl values(, %edi, 4), %eax #second element of array label: values loaded in eax
// if edi=0 it would have been the first element
cmp %ebx, %eax
cmova %eax, %ebx
inc %edi
cmp $4, %edi
jne loop
Instead of looping through the
instructions to look for the largest value four times, you can unroll the loop into a series of four moves:
movl values, %ebx
movl $values, %ecx
movl (%ecx), %eax
cmp %ebx, %eax
cmova %eax, %ebx
movl 4(%ecx), %eax
cmp %ebx, %eax
cmova %eax, %ebx
movl 8(%ecx), %eax
cmp %ebx, %eax
cmova %eax, %ebx
movl 12(%ecx), %eax
cmp %ebx, %eax
cmova %eax, %ebx
While the number of instructions has greatly increased, the processor will be able to feed all of them
directly into the instruction prefetch cache, and zip through them in no time.
Be careful when unrolling loops though, as it is possible to unroll too many instructions, and fill the
prefetch cache. This will force the processor to constantly fill and empty the prefetch cache.
HOME PAGE